函数定义、函数的参数、函数的默认参数
本文共 2936 字,大约阅读时间需要 9 分钟。
函数定义
为什么使用函数
降低编程难度- 通常将一个复杂的大问题分解成一系列的小问题,然后将小问题划分成更小的问题,当问题细化为足够简单时,我们就可以分而治之。各个小问题解决了,大问题就迎刃而解了。 代码重用
- 避免重复劳作,提供效率
定义函数:def 函数名();
调用函数:函数名() 解释说明:python 中使用 def 命令创建一个函数,也就是 "定义"(define)的意思,调用函数其实就是执行函数中的代码 注意事项:函数名的定义跟变量的命名规则一样,函数名由字母、数字、下划线组成,不能以数字开头,不可以使用关键字。另外,当函数名有两个单词时,我们一般把第二个单词的首字母大写来表示这是一个函数(形成一种规范),如:isNum、hanShu、myName 等等,在后面的类中我们则是把所有首字母都写出大写来表示这是一个类,如:IsNum、HanShu、MyName 等等def fun(): print 'hello world'fun()结果:hello world
函数的参数
形式参数和实际参数
- 在定义函数时,函数名后面括号中的变量名称叫做“形式参数”,或者称为“形参”
- 在调用函数时,函数名后面括号中的变量名称叫做“实际参数”,或者称为“实参”

函数的默认参数
1、
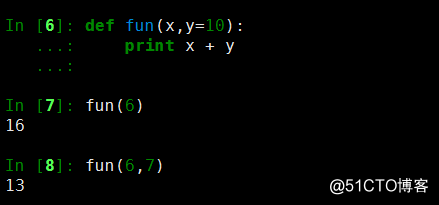
2、
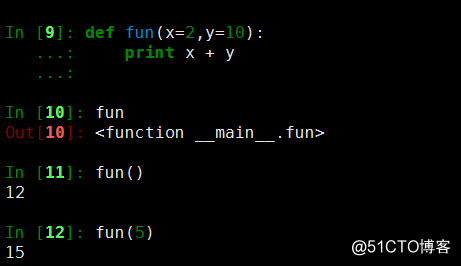
3、 默认值必须放在最后,否则会报错
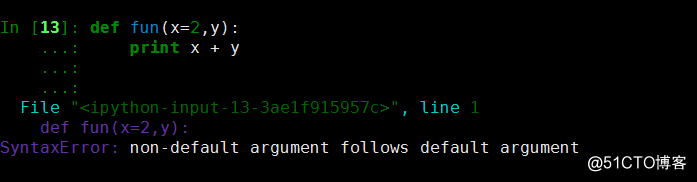
string方法
In [1]: import string
In [2]: text = "Monty Python's Flying Circus" In [3]: string.upper(text) #变为大写 Out[4]: "MONTY PYTHON'S FLYING CIRCUS" In [5]: string.lower(text) #变为小写 Out[5]: "monty python's flying circus"In [8]: string.split(text) #分割
Out[8]: ['Monty', "Python's", 'Flying', 'Circus']In [12]: string.replace(text,'Python','java') #替换文本
Out[12]: "Monty java's Flying Circus"In [15]: string.count(text,'P') #计算字符个数
Out[15]: 1In [16]: string.lowercase #所有小写字母
Out[16]: 'abcdefghijklmnopqrstuvwxyz'In [17]: string.uppercase #所有大写字母
Out[17]: 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'In [18]: string.join(string.split(text), "+") #分割符号
Out[18]: "Monty+Python's+Flying+Circus"In [19]: string.digits #所有数字
Out[19]: '0123456789'练习:
1、# 1. 设计一个函数,统计任意一串字符串中数字字符的个数 #例如: #"adfdfjv1jl;2jlk1j2" 数字个数为4个 思路:1、导入string方法,遍历字符串是否是数字,如果是则加上1,然后打印import string
def getNumtime(text): num=0 for i in range(0,len(text)): if text[i] in string.digits: num+=1 print 'num is {0}'.format(num) getNumtime('adfdfjv1jl;2jlk1j21112')2、# 2. 设计函数,统计任意一串字符串中每个字母的个数,不区分大小写
#例如: #"aaabbbcccaae111" #a 5个 #b 3个 #c 3个 #e 1个思路:1、导入string
2、创建一个函数,将统一变为大写字母 3、创建一个字典,遍历所有的大写字母,添加到字典中 4、计算字母的 个数 方法: In [28]: string.ascii_uppercase Out[28]: 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'def getLettersCount(text):
text = text.upper() #转换成大写 dict1 = dict() #创建空字典 for i in string.ascii_uppercase: dict1.setdefault(i, 0) #将26个字母当做key增加到字典中,value为0for i in xrange(0, len(text)): #遍历字符串 if text[i] in string.ascii_uppercase: #如果在26个字母中 dict1[text[i]] += 1 #value加1for k in dict1: if dict1[k] != 0: #不为0的字母,打印出来 print("{0} {1}".format(k, dict1[k])) 方法二:
In [37]: map(tmp.upper().count, string.ascii_uppercase) Out[37]: [1, 0, 0, 4, 1, 3, 0, 0, 1, 1, 0, 0, 0, 0, 1, 2, 1, 0, 4, 0, 0, 0, 1, 0, 0, 0]In [38]: x=[1,2,3]
In [39]: y=['q', 'w', 'e'] zip合并为 In [40]: zip(x,y) Out[40]: [(1, 'q'), (2, 'w'), (3, 'e')]将列表转换为字典
In [42]: dict2=dict([(1,2),(3,4)]) In [43]: dict2 Out[43]: {1: 2, 3: 4}dict1={'A':1,'B':2}
import string def getsckcount(tmp): dict1=dict(zip(string.ascii_uppercase,map(tmp.upper().count,string.ascii_uppercase))) for k in dict1: if dict1[k]!=0: print '{0} {1}'.format(k,dict1[k]) while True: tmp=raw_input('Please string: ') if tmp!="quit": getsckcount(tmp) else: break本文转自 jiekegz 51CTO博客,原文链接:http://blog.51cto.com/jacksoner/2056731
转载地址:http://nfwsx.baihongyu.com/
你可能感兴趣的文章
控制子窗口的高度
查看>>
处理 Oracle SQL in 超过1000 的解决方案
查看>>
Alpha线性混合实现半透明效果
查看>>
chkconfig 系统服务管理
查看>>
ORACLE---Unit04: SQL(高级查询)
查看>>
贪食蛇
查看>>
201521123009 《Java程序设计》第11周学习总结
查看>>
Python3之多线程学习
查看>>
MVC和MTV结构分析
查看>>
(转)微信网页扫码登录的实现
查看>>
mariadb启动报错:[ERROR] Can't start server : Bind on unix socket: Permission denied
查看>>
nginx的信号量
查看>>
云im php,网易云IM
查看>>
河南农业大学c语言平时作业答案,河南农业大学2004-2005学年第二学期《C语言程序设计》期末考试试卷(2份,有答案)...
查看>>
c语言打开alist文件,C语言 文件的打开与关闭详解及示例代码
查看>>
c语言 中的共用体和结构体如何联合定义,结构体(Struct)、联合体(Union)和位域
查看>>
SDL如何嵌入到QT中?!
查看>>
P1026 统计单词个数
查看>>
[js高手之路] html5 canvas系列教程 - 状态详解(save与restore)
查看>>
poi excel 常用api
查看>>